Actualités
Mini-symposium JOBIM 2026 "Interactions internationales en bioinformatique"
Publié le
Intitulé complet : Mini-symposium JOBIM 2026 "Interactions internationales en bioinformatique autour des technologies de séquençage appliquées à la santé et à l’agriculture"
Date : 2 juillet (après-midi) pendant JOBIM 2026 à Strasbourg
Ce mini-symposium propose une session thématique consacrée aux interactions internationales portées par la Société Française de Bioinformatique (SFBI). Il a pour objectif de favoriser les échanges scientifiques et institutionnels entre communautés de bioinformatique et de biologie computationnelle.
Dans un contexte où les collaborations internationales jouent un rôle central dans le développement de projets interdisciplinaires et l’émergence de nouvelles approches méthodologiques, cette session offrira un espace de discussion structuré autour des enjeux, opportunités et défis associés à ces coopérations, notamment dans les domaines de la santé et de l’agriculture.
Deux professeur·e·s partageront leurs travaux de recherche et leur vision des dynamiques internationales en bioinformatique :

Professeure Ana Tereza Ribeiro de Vasconcelos, chercheuse senior au Laboratoire National de Calcul Scientifique (LNCC, Laboratório Nacional de Computação Científica), qui dépend directement du Ministère brésilien de la Science, de la Technologie et de l'Innovation. Elle dirige le Laboratoire de bioinformatique du LNCC et l'unité de génomique computationnelle Darcy Fontoura de Almeida. Elle est membre titulaire de l'Académie brésilienne des sciences (ABC, Brazilian Academy of Sciences), membre de la Société internationale de biologie computationnelle (ISCB, International Society for Computational Biology) et membre de l’Académie mondiale des sciences pour le développement de la science dans les pays en développement (TWAS, The World Academy of Sciences). Elle a été la première présidente de l'Association brésilienne de bioinformatique et de biologie computationnelle (AB3C, la société brésilienne de bioinformatique).

Professeur Justin PITA est Professeur Associé au département de pathologie végétale et de microbiologie environnementale du College of Agricultural Sciences de Pennsylvania State University (USA) et Maître de Conférences à l’Université Félix HOUPHOUËT-BOIGNY (Côte d’Ivoire). Il cumule plus de 25 ans d’expérience dans la recherche sur la santé des plantes, particulièrement sur l’épidémiologie des maladies virales et l’évolution des virus, dans des institutions de renom aux États-Unis et en Afrique, comme WAVE (Central and West African Virus Epidemiology) dont il est le Fondateur et le Directeur Exécutif. WAVE est présent dans 14 pays d’Afrique du centre et de l’ouest (ACO) regroupant 17 centres de recherche et universités. Son programme de recherches pour le développement en ACO porte sur le diagnostic et la surveillance des pathogènes des plantes intégrant des approches de séquençage haut débit, la modélisation et la bioinformatique ainsi que sur le renforcement des capacités infrastructurelles et humaines.
Les interventions seront suivies de présentations très courtes par des scientifiques du Brésil et d'Afrique Centrale et de l'Ouest, puis d’un temps d’échange visant à identifier et discuter les perspectives de futures collaborations et interactions entre nos réseaux.
Ce mini-symposium s’adresse à l’ensemble des participant·e·s intéressé·e·s par les dimensions collaboratives, organisationnelles et scientifiques de la bioinformatique et de la biologie computationnelle. Les partenariats envisagés pourront prendre différentes formes : montage de projets communs, accueil croisé de scientifiques, ou encore organisation de workshops et de formations communes sur les thématiques pour lesquelles des besoins seront identifiés. Un focus sera porté sur les enjeux liés à la gestion des données, aux infrastructures de calcul et aux principes de la science ouverte.
La participation est ouverte à l’ensemble des participants de JOBIM. Le mini-symposium sera accessible en visioconférence.
Programme
15h - 15h05 : Introduction
15h05 - 15h45 : Bioinformatics in Brazil: From genomic networks to multiomics integration: building science in a megadiverse nation - Professeure Ana Tereza Ribeiro de Vasconcelos
15h45 - 16h : 3 présentations Flash Brésil
1) Program's Coding: The Code of Life - A pilot project for applying bioinformatics in high school education - Helena Lott Costa Rocha
2) Plant Parasitism and Metal Transport: Complementary Narratives of Evolution and Molecular Innovation in Plants - Wenderson Felipe Costa Rodrigues
3) EpiBuilder 2.0: A Dockerized Web Platform for In Silico Prediction and Analysis of Linear B-Cell Epitopes - Bruna Caroline Russi
16h - 16h30 : pause
16h30 - 17h10 : Bridging the gap in computational biology: genomic surveillance and bioinformatic innovation for plant health and food security in Africa - Professeur Justin PITA
17h10 - 17h30 : 3 présentations Flash Afrique de l'Ouest
1) A Spatially Explicit Delay-Differential Framework for Optimal Disease Surveillance in Clonally Propagated Plants - Koissi SAVI
2) Enhancing Genomic Prediction Accuracy for Complex Traits in Cassava (Manihot esculenta) Through Pangenome-Informed Variant Calling - Oloruntoba Isaac ABEGUNDE
3) Optimizing de novo assembly of RCA-enriched circular ssDNA viral genomes using long-read sequencing - Pakyendou Estel NAME
17h30 - 17h50 : table ronde sur les enjeux scientifiques (gestion, science ouverte, collaborations et les connexions possibles entre ces différents réseaux)
Organisat·eur/rice·s & Sponsors
AB3C : Marcello Mendes Brandão, Fabrício Martins Lopes
SFBI : Sandra Dérozier, Anna-Sophie Fiston-Lavier, Charles Lecellier, Marie-France Sagot
IFB : Hélène Chiapello, Jacques van Helden
IRD : Julie Orjuela, Ndomassi Tando, Christine Tranchant-Dubreuil
LNCC : Ana Tereza Robeiro de Vasconcelos
Université Joseph Ki-Zerbo : Romaric Kiswendsida Nanema
WAVE : Angela Eni, Ezéchiel Tibiri, Fidèle Tiendrebeogo

Collaboration SFBI & Métal Hurlant
Publié le
L’ADN dans tous ses états : un dialogue entre science, art et société
En 2027, le CNRS organisera l’année thématique « L’ADN dans tous ses états », une initiative dédiée à explorer les multiples dimensions de cette molécule essentielle, des avancées scientifiques aux enjeux sociétaux. Coordonnée par les Groupes de Recherche du CNRS Bioinformatique Moléculaire: Modélisation et Méthodologie (BIMMM) et Informatique Fondamentale et ses Mathématiques (IFM), en partenariat avec la Société Française de BioInformatique (SFBI), cette année promet de rassembler chercheurs, artistes et citoyens autour d’une réflexion collective.
Un numéro spécial avec Métal Hurlant : quand la science inspire l’art
Dans ce cadre, la SFBI s’associe à la revue mythique Métal Hurlant, où science, art et narration se croisent depuis des décennies. L’objectif ? Créer un numéro spécial dédié à l’ADN, où des trinômes chercheur-scénariste-dessinateur collaboreront pour donner vie à des récits visuels et littéraires inédits. Ces collaborations, facilitées par le collectif La Coulisse, exploreront les thèmes de nos recherches et pourront être aussi variés que :
- l’intelligence artificielle appliquée à l’ADN,
- les modifications génétiques par CRISPR,
- la biologie de synthèse,
- la métagénomique,
- l'évolution,
- le stockage de l’information sur molécule d’ADN,
- etc.
Allier rigueur scientifique et liberté créative
Ce projet ambitionne de démocratiser la complexité tout en suscitant curiosité, émotion et réflexion. En associant chercheurs (doctorants, post-doctorants, chercheurs statutaires) et créateurs, il s’agit de proposer une plongée dans l’ADN à la fois informative, sensible et stimulante pour partager le fruit de nos recherches de manière innovante et accessible.
Processus de sélection des propositions
Les propositions seront évaluées en deux temps : un comité scientifique ad hoc examinera d’abord leur pertinence thématique, leur originalité et leur cohérence pédagogique, avec la possibilité de fusionner certaines d’entre elles pour enrichir leur portée. Les projets présélectionnés seront ensuite soumis à la rédaction de Métal Hurlant, qui effectuera une sélection finale fondée sur leur force narrative et leur potentiel visuel. Compte tenu de ces contraintes éditoriales, certaines propositions ne pourront malheureusement pas être retenues dans ce numéro spécial.
En participant à ce projet, vous vous engagez à :
Ce qu’on attend de vous
- Disponibilité et réactivité : participez aux échanges et réunions pour éclairer les artistes sur les aspects scientifiques, tout en respectant leur processus créatif ;
- Ouverture d’esprit : acceptez que les récits explorent des angles originaux, parfois éloignés d’une vision strictement académique ;
- Flexibilité : certaines propositions pourront être fusionnées, impliquant des équipes de chercheurs plutôt que des contributions individuelles.
Pour participer (date limite 22 Avril 2026) : https://www.sfbi.fr/survey/index.php?r=survey/index&sid=388832&newtest=Y&lang=fr.
Enquête MERIT / SFBI sur les conditions de travail des bioinformaticiens.nes
Publié le
Huit ans après la première réflexion lancée par la SFBI dans le cadre du groupe de travail (GT) MetBif (Métier de la Bioinformatique), qui a conduit en 2021 à la rédaction d’une première fiche métier (https://zenodo.org/records/5513972#.YZ9qPVPjJKM ), le GT métier de MERIT et la SFBI ont proposé, en février 2026, une enquête sur les conditions de travail des bioinformaticien·ne·s.
L'objectif de ce sondage était de dresser un panorama global des conditions de travail des bioinformaticiens et bioinformaticiennes évoluant dans différents instituts de recherche et entreprises privées.
Cette enquête, menée auprès des professionnels de la bioinformatique (250 réponses), offre un aperçu détaillé de la diversité des profils, des environnements de travail et des préoccupations majeures en termes de reconnaissance, de formation et de salaires de la communauté en France.
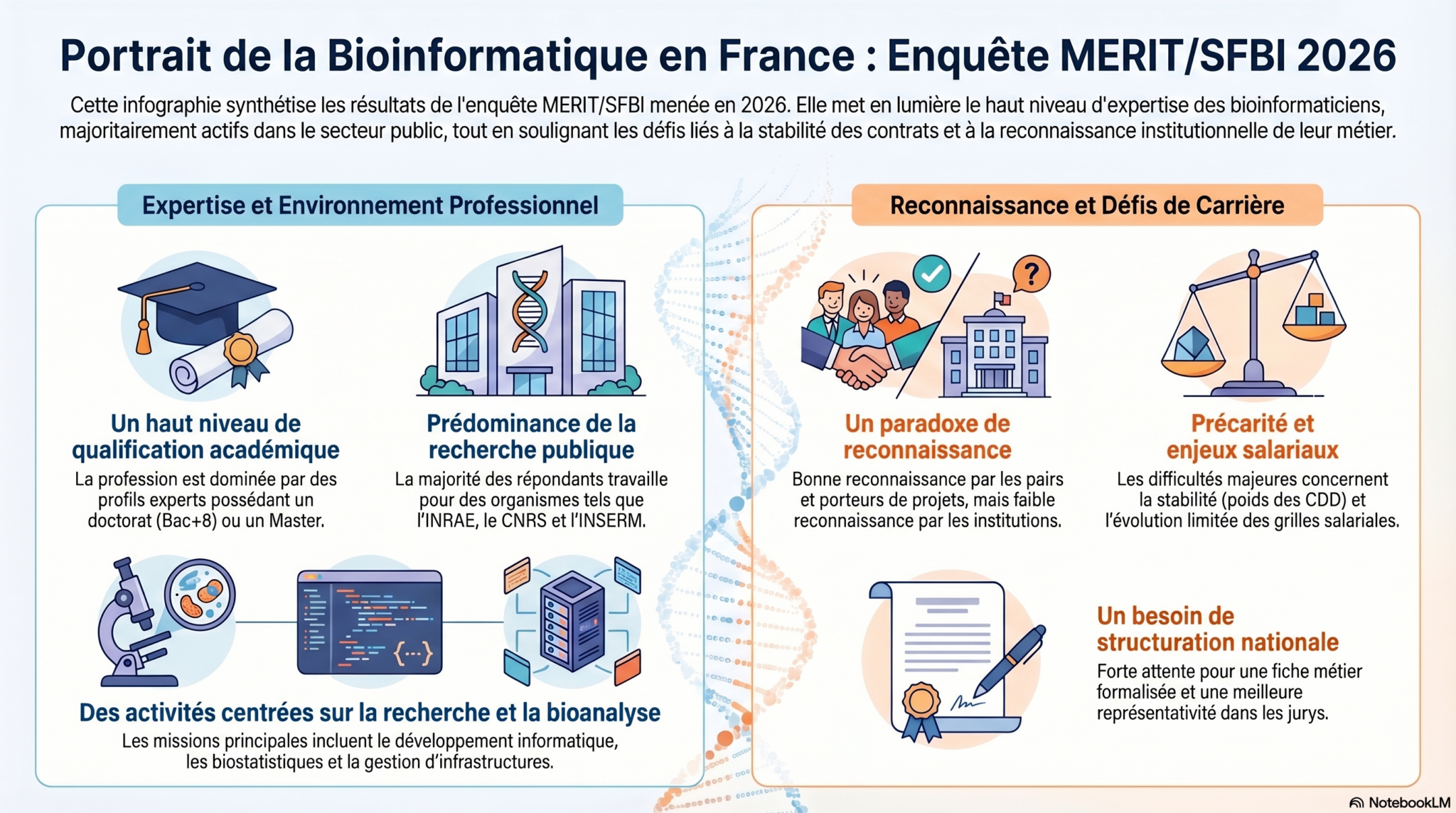
L'ensemble des résultats de cette enquête est accessible sur le site web MERIT : https://merit.cnrs.fr/enquete-merit-sfbi-sur-les-conditions-de-travail-des-bioinformaticiens-nes/
REBIF 2026
Publié le
Qu’est-ce que REBIF ?
Depuis 2016, les enseignants-chercheurs et chercheurs, acteurs et responsables de formations académiques en bioinformatique ont souhaité se réunir afin de lister et discuter des formations proposées en France. La "Rencontre autour de l'Enseignement en BioInformatique en France" (REBIF) est organisée sous le joug de la SFBI et de l'IFB.
Une des actions de REBIF est d’établir la liste exhaustive des formations diplômantes en bioinformatique de tous niveaux (DUT, Licences, Master, Ingénieur, DU), sous forme de fiches formations standardisées, avec des mots-clefs permettant de caractériser chaque formation et ainsi faciliter l’orientation des étudiants.
Ces fiches, présentant le paysage actuel des formations et de leurs spécificités, ainsi qu’une carte de France des formations, seront rendues publiques sur le site de la SFBI, et viendront compléter le listing maintenu par l'association des Jeunes Bioinformaticiens de France (JeBiF).
REBIF 2026, pourquoi ?
Nous proposons aux responsables des formations diplômantes en bioinformatique de se réunir cette année pour une nouvelle édition avant les JOBIM2026 les lundi 29 juin après-midi et mardi 30 au matin afin de :
préparer la mise à jour de la liste existante des formations diplômantes en bioinformatique ;
présenter des outils/plateformes existantes (catalogues de formations, fiches métiers, offres d'emploi SFBI, ...) ;
faire le lien entre les formations et les métiers de la bioinformatique ;
partager nos expériences autour des ressources matérielles et logicielles d'IA pour les enseignements (apprentissage, modalités de contrôle des connaissances) ;
réfléchir à l'évolution des contenus des formations en bioinformatique en lien avec l'arrivée de l'IA.
Programme prévisionnel des REBIF2026
Lundi 29 juin 2026
14h00 - 14h30 : tour de table par formation/université/structure
14h30 - 15h : présentation des « outils » existants
- catalogues de formations existants (IFB/JeBiF/SFBI)
- fiches métiers (SFBI/BioInfoDiag/MERIT)
- bilan des offres d’emploi des dernières années (SFBI)
15h00 - 16h15 : atelier #1 - Nouvelles compétences attendues & Évolution des métiers en bioinformatique
16h15 - 16h45 : pause café
16h45 - 17h45 : atelier #2 - Séance de travail pour définir un formulaire de recensement des formations (alimentation d’un catalogue des formations en France et dans les pays francophones)
Pour celles et ceux qui le souhaitent, nous proposons de nous retrouver pour un dîner en ville (chacun·e règle sa consommation). Un restaurant sera proposé sur place.
Mardi 30 juin 2026
8h45 - 9h00 : introduction IA & enseignement
9h00 - 10h15 : atelier #3 - Place de l’IA dans les contenus de formation
10h15 - 10h45 : pause café (enregistrement à la conférence JOBIM)
10h45 - 12h00 : atelier #4 - Ressources matérielles pour l’IA pour les enseignements
Modalités d'inscription
L'inscription à cet événement est gratuite mais obligatoire. Elle sera couplée à celle à la conférence JOBIM2026 (ouverture des inscriptions : 30 avril 2026).
Si vous ne pouvez pas participer à l'événement REBIF2026 mais que vous êtes intéressé·e par cette initiative, merci de remplir ce court formulaire en ligne.
Comité d'organisation
SFBI : Sandra Dérozier, Anna-Sophie Fiston-Lavier, Delphine Potier
IFB : Hélène Chiapello, Jacques van Helden
JeBiF : Savandra Besse, Vinh-Son PHO
Bénévoles pour l'animation d'ateliers : Emmanuelle Becker, Emmanuel Talla
Sophie Schbath nommée ISCB Fellow 2026
Publié le
La SFBI se réjouit de la nomination de Sophie Schbath en tant qu'ISCB Fellow 2026 !
Sophie a été présidente de la SFBI de 2011 à 2015. Elle a grandement contribué à l'animation et au dynamisme de notre communauté, aussi bien du point de vue scientifique qu'humain. Il nous a semblé tout à fait pertinent de proposer le nom de Sophie pour cette distinction.
Merci à l'ISCB de mettre à l'honneur un membre de notre si belle communauté !
Plus d'informations : https://www.iscb.org/about-iscb/society-communications/announcements/april-21-2026-iscb-announces-the-2026-class-of-fellows